This is a preview chapter from the next batch of chapters about indexing myths for my
book about database indexes
. My goal is to teach the needed information to create good indexes in a much more understanding way without any technical complexities.
🎁 50% discount until Black Friday.
With all previous chapters, the idea was to build indexes and change the schema so rows read from a table utilize an index. And this approach is entirely valid. There isn't a groundbreaking new thing that invalidates anything you've learned.
However, most developers still believe only one index can be used simultaneously for each table, but commercial databases have supported multiple indexes (called “index merge”) for a very long time. Even open-source databases like PostgreSQL (2005) and MySQL (2015) added them long ago.
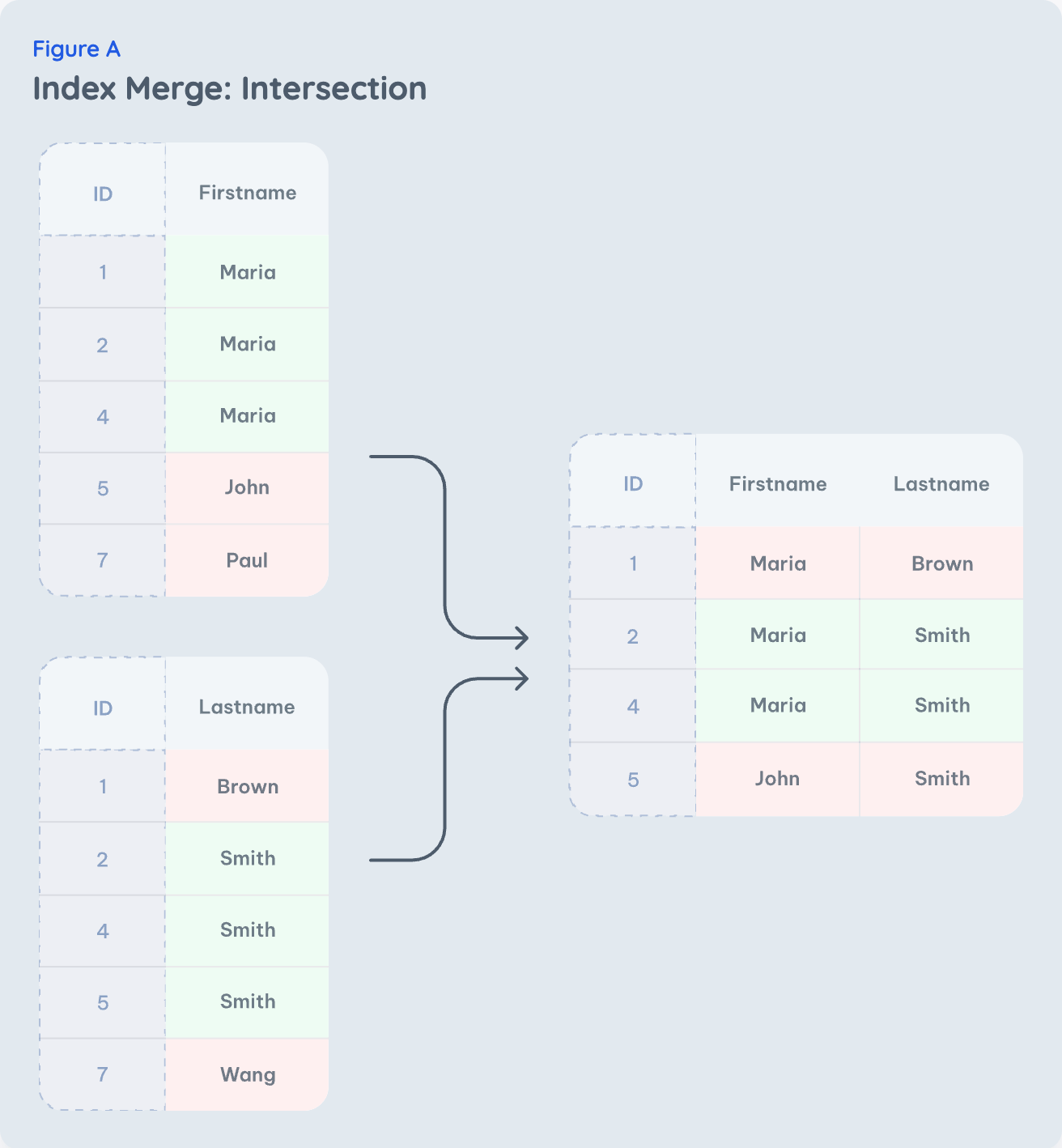
A typical example of the intersection of multiple indexes is a condition like
firstname = 'Maria' AND lastname = 'Smith'
: With most schemas, someone created one index on the first name column and one on the last name - which is not efficient as only one of the conditions is improved by the index. A single-column index is never what you need!
However, the developers of databases have recognized that this is a widespread issue and are trying their best to nevertheless improve the performance of this query - although you should just create a better index. The idea is simple: Both indexes are used independently to check which index entries match a subset of the conditions. These results are then merged by checking that all indexes matched for the same ID (Fig. A).
This optimization requires two or more indexes each matching many rows: But selecting one of these indexes would result in loading and discarding many from the table because those rows would fail the other conditions of the query. The matching index entries must be predicted to be reduced significantly by the other indexes. This is hard to guess for the database, so optimization is not often applied.
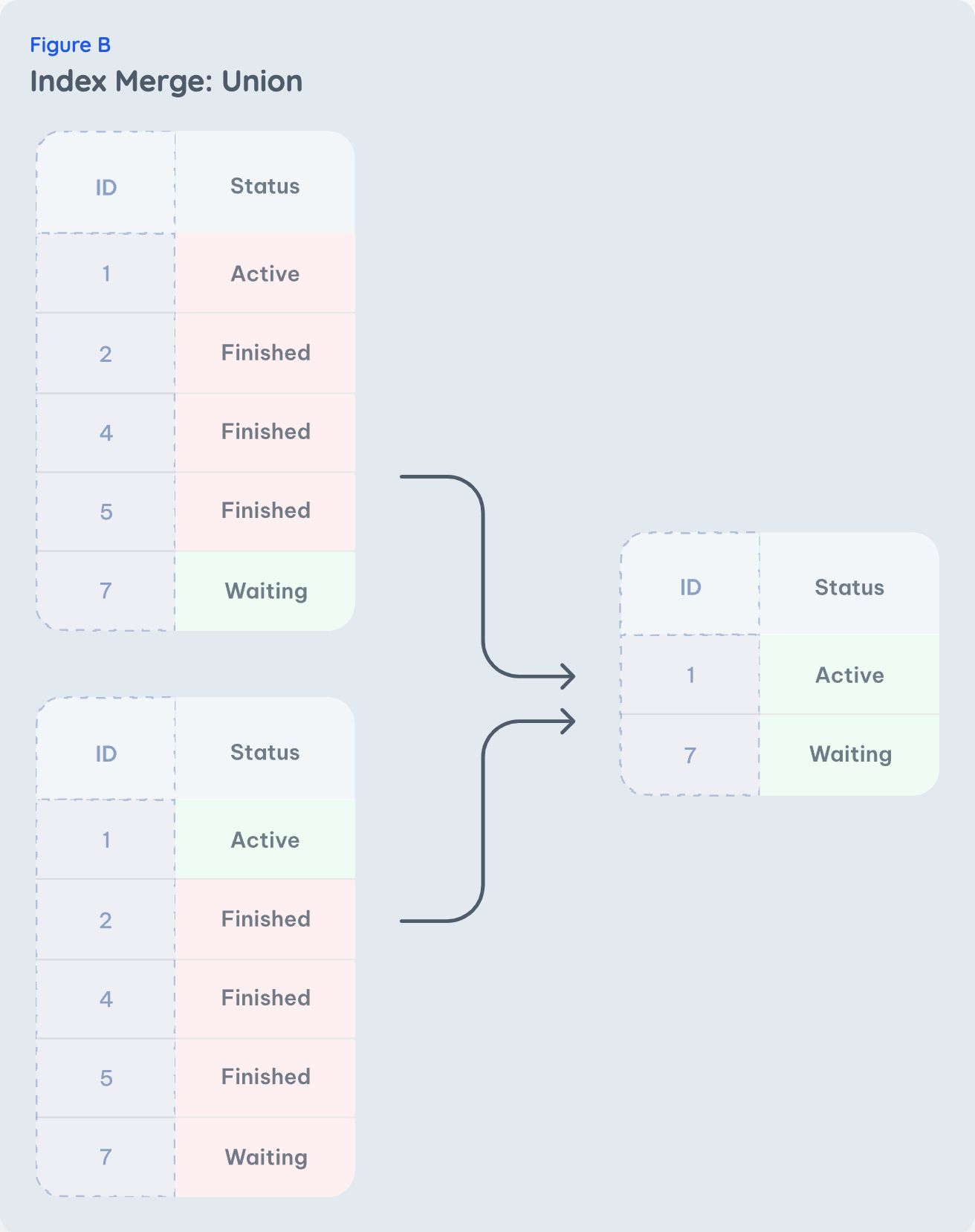
Another common issue is OR conditions like
status = 'active' or status = 'waiting'
. For this query, the same index can be used multiple times for the different conditions with the index merge optimization. This works exactly as you expect: The results of scanning the active for the
active
and
waiting
status are just appended together (Fig. B). Nothing more to do.
For this to be used by a database, the amount of matches by all indexes (or index invocations) should be relatively small otherwise a full table scan could be more efficient (chapter 4. “Why Isn’t the Database Using My Index?”).