Index Access Principle #3: From Left to Right
This is my favorite chapter from my
book about database indexes
. My goal is to teach the needed information to create good indexes in a much more understanding way without any technical complexities.
🎁 50% discount until Black Friday.
An index on a single column is simple, easy to understand and nobody has problems using them. The real problem and performance improvement opportunity is always with multi-column indexes - also called composite indexes. They are the most tricky feature of database indexing and the least-known concept among developers. Once you have mastered using them, you can fix all slow queries yourself. Because of this, the entire book will explain most indexing
functionality based on multi-column indexes.
The rule for multi-column indexes can be summarized as
“From Left to Right Without Skipping a Column”
. This simple sentence describes precisely how these indexes are used to speed up queries. However, it is hard to fully understand.
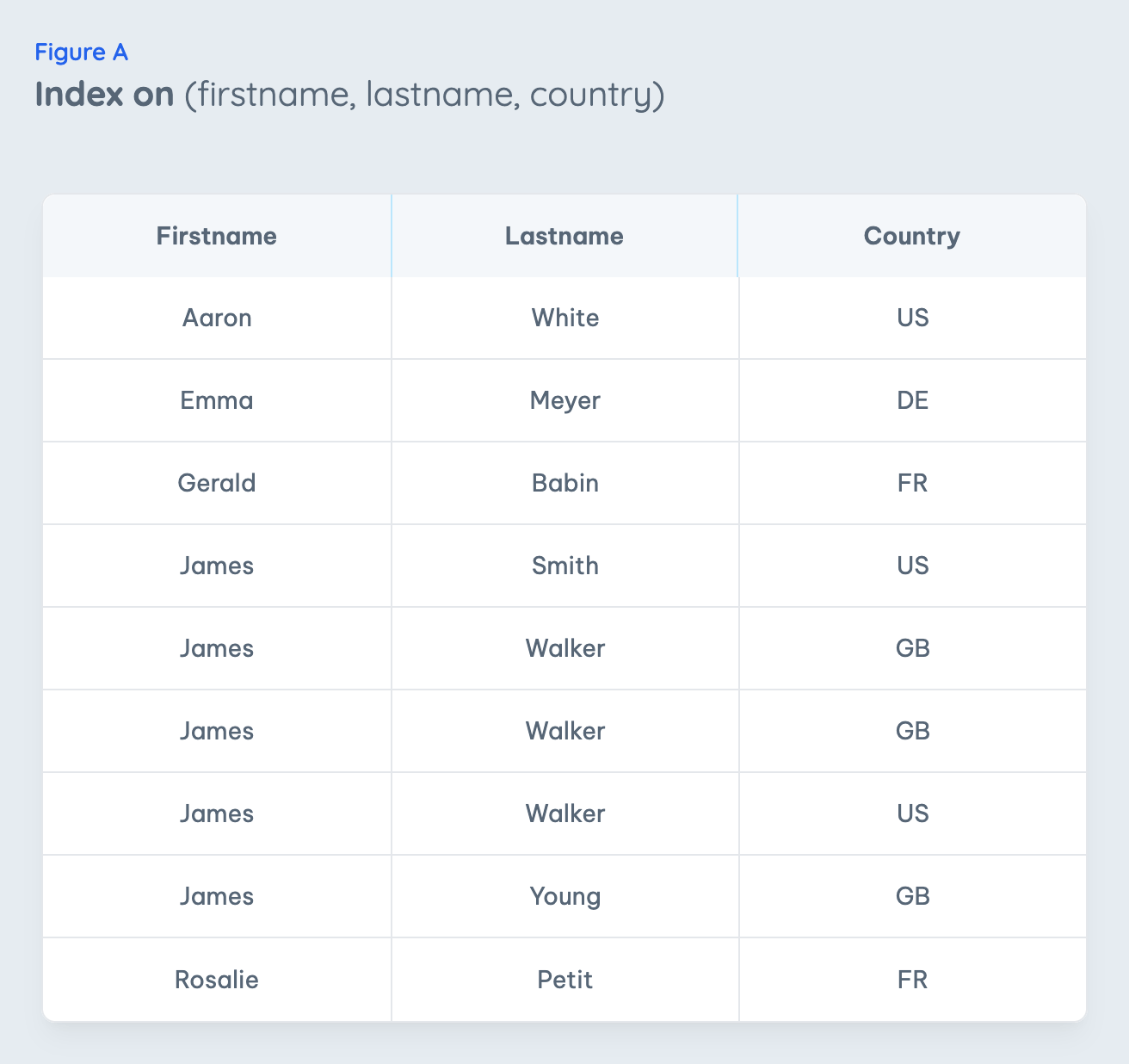
The fundamental constraint is that the index of Fig. A can only be used to speed up a certain type of queries:
SELECT * FROM contacts WHERE firstname = 'James'SELECT * FROM contacts WHERE firstname = 'James' AND lastname = 'Walker'SELECT * FROM contacts WHERE firstname = 'James' AND lastname = 'Walker' AND country = 'US'
Indexes Are Used From Left to Right
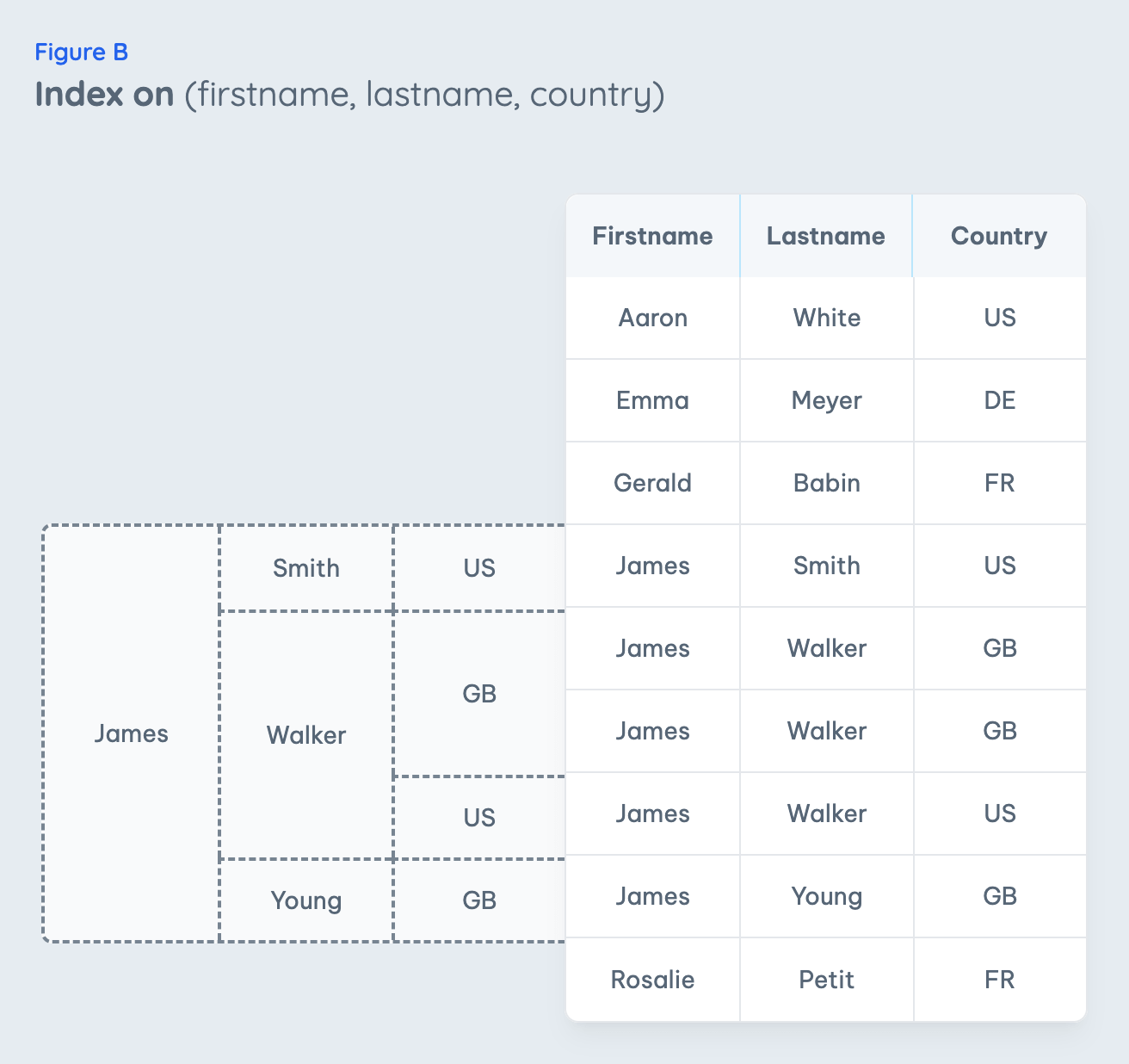
It is important to remember that index entries are always sorted by the value of the first column, all duplicate values are then by the second one and so on. The index summary can then be imagined as a funnel to narrow down the offset within the index by each column (Fig. B).
The condition
firstname = 'James' AND lastname = 'Walker' AND country = 'US'
is executed like:
-
Start at the top of the index by choosing the funnel for
firstname = 'James'
-
For the
lastname = 'Walker'
condition, choose now the middle row in the second column of the funnel. The row above for Smith and below for Young are now ignored as they can't have a result for the WHERE conditions.
- Go one step further to the right on the funnel and choose from the options GB and US the last one.
Finding the correct index entry was very easy with the funnel-searching approach. But hallucinating a funnel for doing this step so effortlessly sounds like cheating - it can't be what the database is doing. In reality, the database is doing something exactly like that with its hierarchies of index summaries explained before. The funnel imagination is just abstracting some B+ tree behavior from a complicated technical implementation to an easy-to-understand
mental image. It is a simple way to decide whether a specific multi-column index would fit a query well.
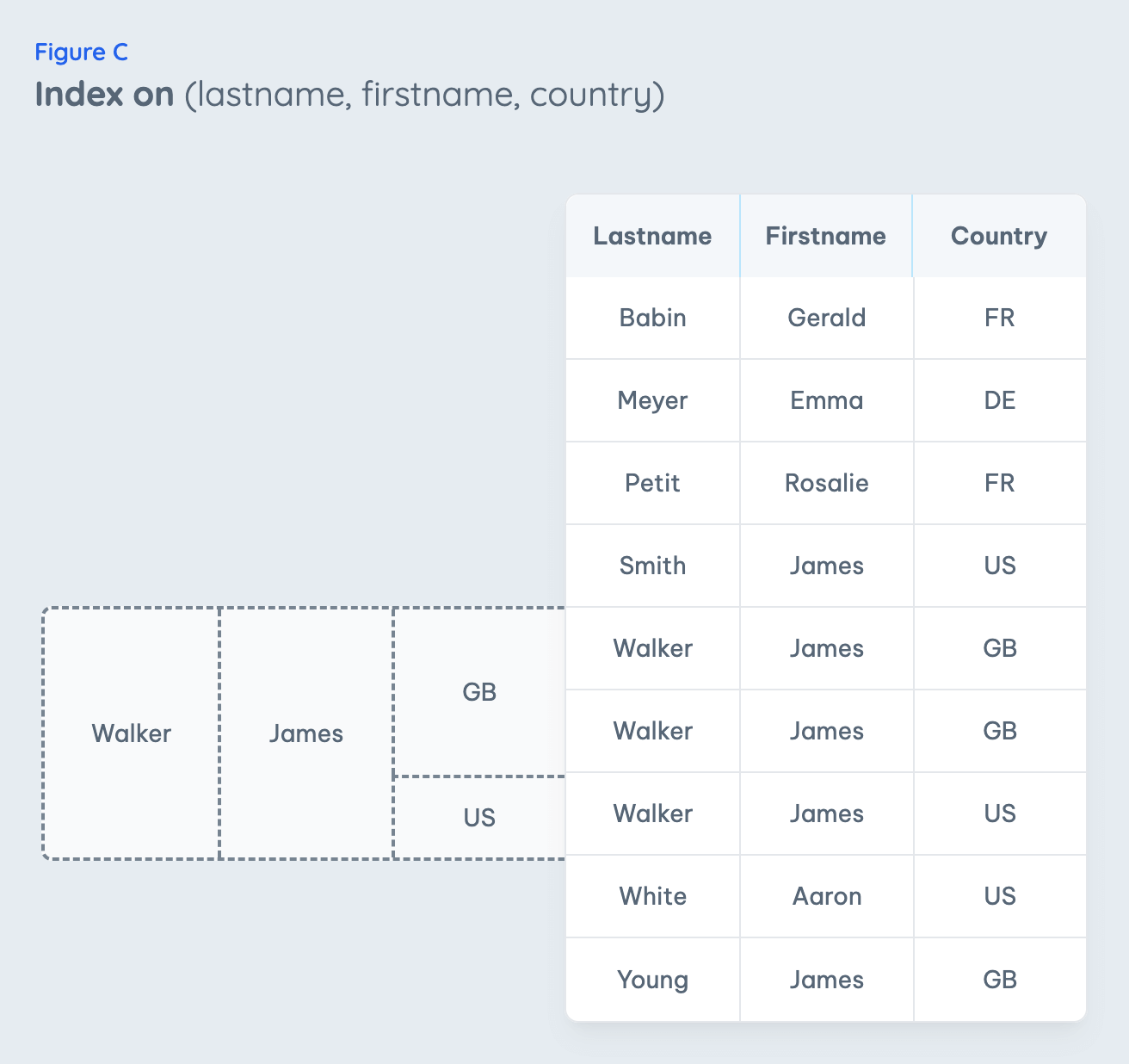
The Ordering Is Important
You will find the incorrect advice again and again that your multi-column index should start with the most selective (most different values) column first. The former index has been rebuilt by this rule (Fig. C). You can see that the number of funnel steps to get to the index entry is still the same - just ordering them by selectivity doesn't make a difference.
But the ordering is still essential as an index has to fulfill your querying needs. If all your queries use all the index columns, the order won't make a difference (except for the next principle in the next chapter). But usually, most of your queries will use a subset of the indexes columns, while a tiny fraction will use all. In these cases, the ordering is critical!
If you want to find all contacts from the United States (
WHERE country = 'US'
), neither the initial index (Fig. B) nor the one ordered by selectivity (Fig. C) can be used. Remember, an index is used from left to right because of the funneling approach. The
country
column would have to be the first one in the index to use the funnel - having them at the end does not help.
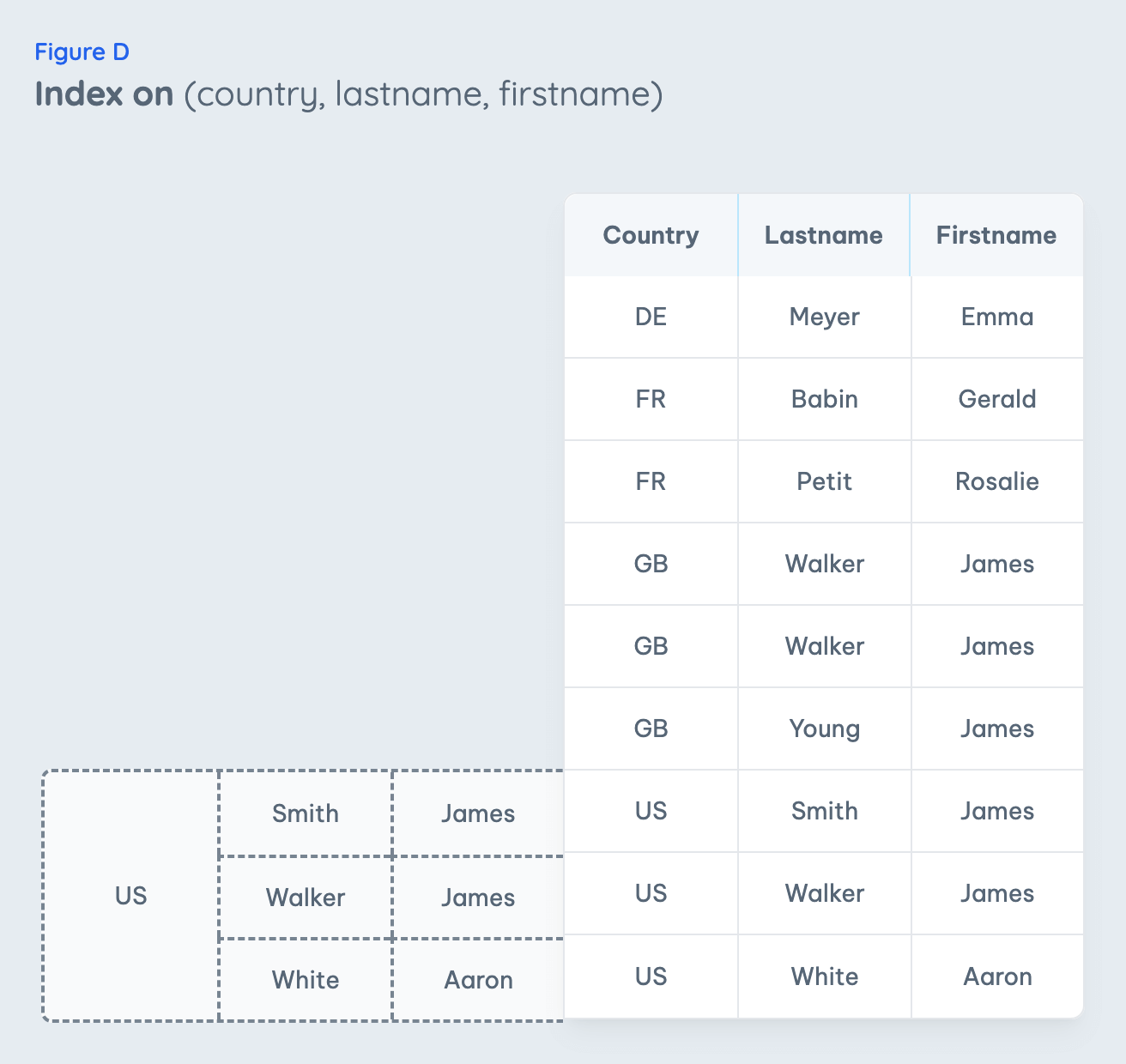
The correct approach to ordering index columns is to cover as many distinct queries as possible. The index of Fig. D is a perfect match if you execute these statements:
SELECT * FROM contacts WHERE country = 'US'SELECT * FROM contacts WHERE country = 'US' AND lastname = 'Walker'SELECT * FROM contacts WHERE country = 'US' AND lastname = 'Walker' AND firstname = 'James'
There is no generic rule to follow for the ordering of index columns. A multi-column index is always built with the left-to-right rule to fit the funnel approach for as many queries as possible. You need to know all queries executed on a table apart from the specific one you may try to optimize currently.
Skipping a Column
There is another common misunderstanding in addition to the selectivity myth explained before. It is believed that a condition like
firstname = 'James' AND country = 'US'
won't use the index
(firstname, lastname, country)
.
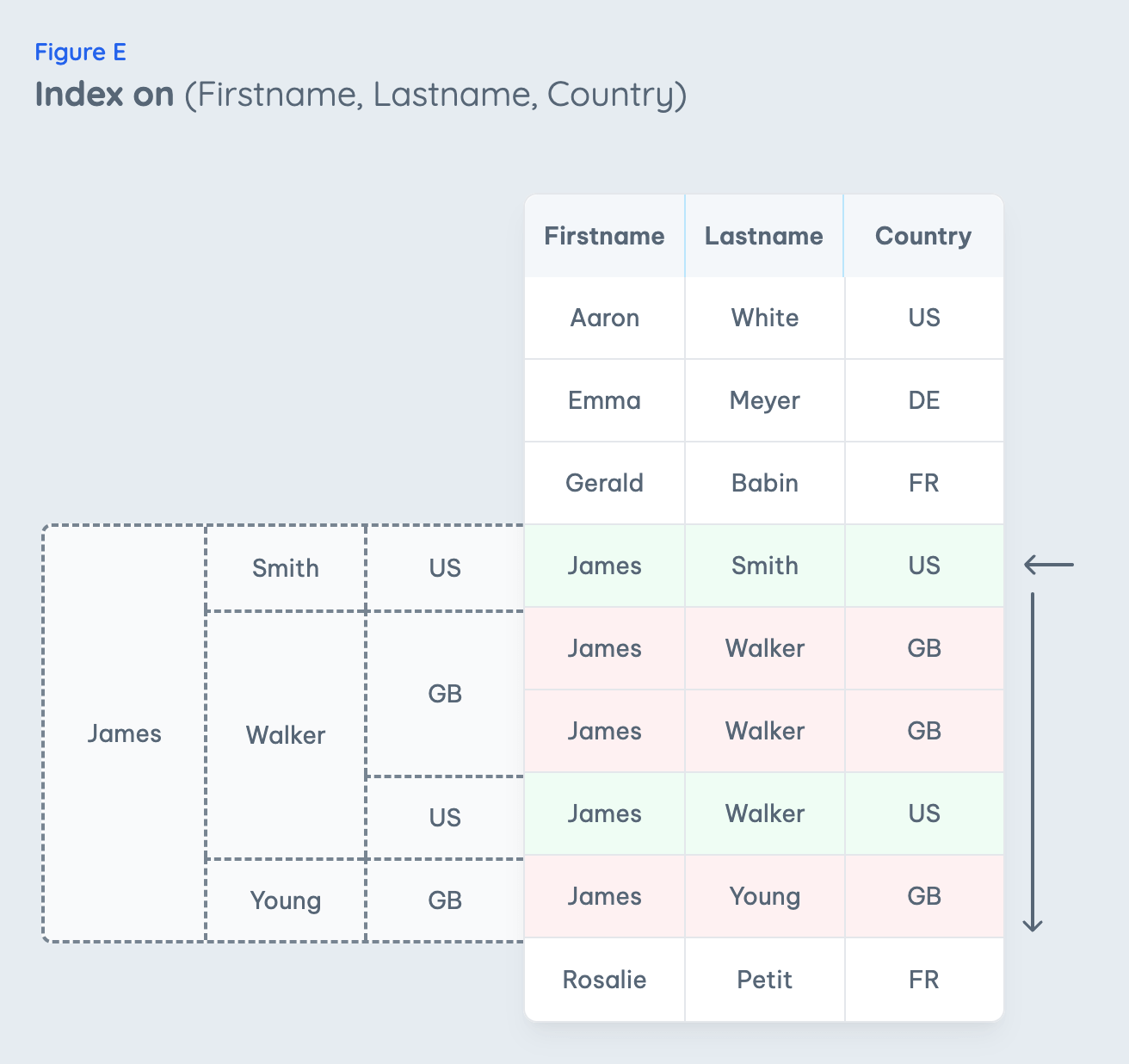
We can see that the index is not fitting for the query when investigating its funnel in Fig. B again. The database can use the
firstname
of the funnel but then can't continue with the next step as a condition on the last name is not used. With a multi-column index, the database can't skip any funnel steps to jump to the matching index entries (principle 1: fast lookup)!
However, the index will still be used by the database but is less efficient than a perfect one on
(firstname, country)
. The steps involved are more complex (Fig. E):
- The database will use as many funnel steps as possible (without skipping a column) to narrow the potential index entries that could match the query. So in this example, there will be a fast lookup to the first index entry of James by using only the first column of the index (principle 1: fast lookup).
- It will then proceed by iterating all index entries for James (principle 2: scan in one direction).
-
Each of these index entries will be validated whether they match the
country = 'US'
condition.
- Only the matching index entries will be used.
This procedure has to iterate over five index entries in this example and keeps only two of them. While the perfect index would have been able to do a fast lookup on the first matching index entry and select both of them by scanning forwards. The difference may not be important for this small example. But in a real application, your index may have hundreds of thousands of index entries for James. Iterating over all of them to keep only the matching ones is
much slower than directly finding the correct index entries when having a fitting funnel.
Although this approach is slower than the perfect index, it is still faster than a single-column index on
(firstname)
. Again a single funnel step and iteration over the five index entries would be done. However, the iteration on the multi-column index can filter on the country column within the index and only load the two table rows that match the condition. The single-column index can't do this pre-filtering and has to load all five rows from the table to filter on the table's
country
column. The single column-index has to load more rows from the table which you want to avoid for best performance. Remember, for real applications, there could be thousands of rows for
James
but only a few would match the condition.
|
💡 Info
“From Left to Right Without Skipping a Column” is a sentence that should be burned into your brain. While the first part of the rule is a requirement, the second one is optional. But for acceptable performance, both of them should be always satisfied!
|
Overlapping Indexes
You may have overlapping indexes in your tables like the last index on
(country, lastname, firstname)
and e.g. a single-column index on
(country)
. Both indexes can be used to search for all contacts from the United States, while the multi-column index can be used for more queries to further narrow down that selection. As indexes need to be changed on every table modification, you should remove the single-column index in this example. You don't get any benefits by keeping it - the multi-column index speeds up the same queries.
This advice is also valid when comparing two multi-column indexes when their ordering is the same but one has more columns included than the other, e.g.
(country, lastname)
can be removed in favor of
(country, lastname, firstname)
. But based on the left-to-right rule, the indexes on
(country, lastname, telephone)
and
(country, lastname, email)
are different because one is not a strict superset of the other.
|