Hello everyone, last month I shared with you my fast analytics course. And as promised, I'm back again four weeks later with another chapter! So this chapter is about creating hypertables and indexes so they are the most efficient.
Whether you're using TimescaleDB hypertables (or partitioning), this chapter is essential for you: When you don't plan your schema and queries precisely, every query must always look into every chunk of your table. So by time all queries get gradually slower and slower. What was fast once is now slow...
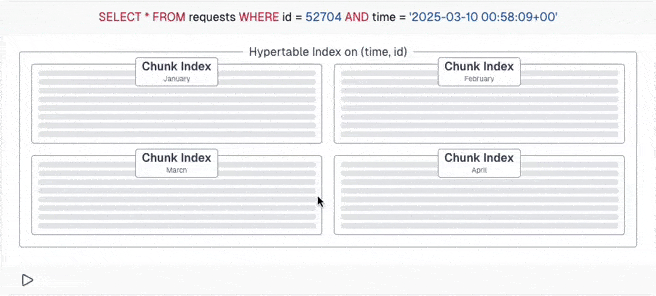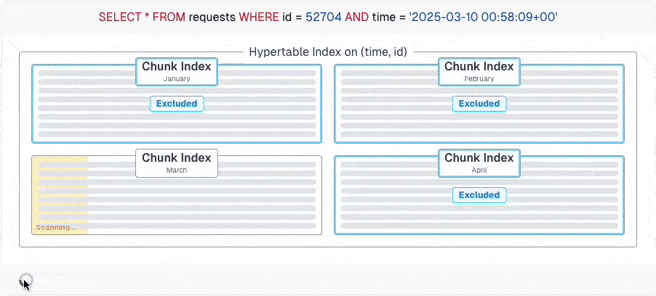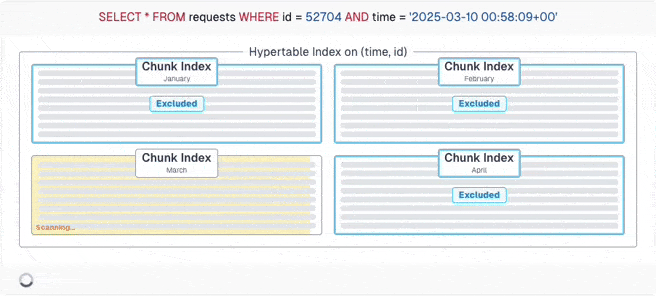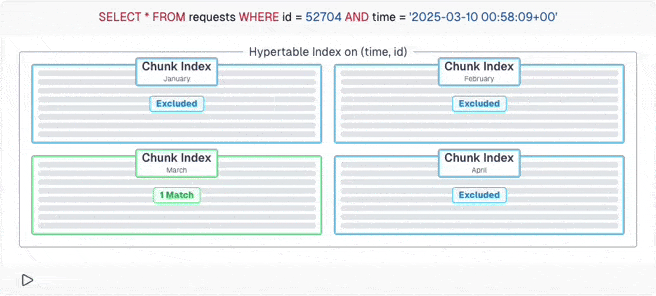
But with careful schema design and writing partition-aware queries, PostgreSQL can calculate which chunks can have the data and only query those. With this example, it's a four times speedup! And with TimescaleDB's chunk skipping, imperfect queries can still ignore many chunks - thanks to the excellent engineering effort from the TimescaleDB developers.
You've probably heard (or used) random UUID (UUIDv4) primary keys for your tables. Although they offer some great benefits for your application, they are awful for performance. But last year, a new standard (RFC 9562) was accepted with new UUID versions: The new UUIDv7 format is perfect for database performance and also for your schema design with TimescaleDB hypertables and partitioning.
That's a rough overview about the course's chapter. So if that sounds interesting to you, please take a look at it and let me know what you think!
I hope you learn a lot
Tobias