Early bird pricing for our Claude Code for Beginners class taught by Dan Shipper on November 19 ends tonight. Save $500 and reserve your spot today.—Kate Lee
Since GPT-5 came out three months ago, my writing workflow has been straddling LLM providers: ChatGPT for drafting, Claude for editing. The setup works, but the back-and-forth is tedious: Copy a draft from one window, paste it into another, wait for feedback, then hop back to revise. I’ve been starting to feel a bit like a glorified traffic conductor.
Then Anthropic dropped Sonnet 4.5, and within 48 hours my workflow collapsed from two chat interfaces into one.
Our Vibe Check on Sonnet 4.5 focused on coding. The model shined in Claude Code, wowing with its speed and handling long agentic tasks and multi-file reasoning without getting lost. And Anthropic followed Sonnet 4.5 closely with Haiku 4.5—a smaller, cheaper model that got our engineers excited for its building implications.
But as much as code and writing have in common—they’re both arranging letters and symbols in rows to achieve specific tasks, after all—code has some objective standards, namely, “Does it run?” Writing is different. There's no "Does it compile?"—the clear signal in programming that tells you if the code works or not—for good prose. Writing is subjective, taste-driven, and full of edge cases where two editors will disagree about what "better" even means.
We spend a lot of time working with AI in writing contexts at Every, whether it’s Spiral general manager Danny Aziz training models to produce stellar copy inside the app, or me yapping at my computer to hammer out first drafts of my essays about work and technology. A byproduct is that we’ve developed a set of benchmarks by assessing how well the new model works within our systems. They aren't objective measures, but they're what we use when we're deciding which model to reach for
So how do we decide whether a model is worth the switch? We run five tests based on our own workflows and what we need the model to do. As a result, they matter more to us than any benchmarks. The tests fall into two categories:
Output (Can it write?): Tests that tell Danny if he can trust Spiral to produce great copy, or I can trust my Working Overtime project to sound “like me” while keeping “AI smell” to a minimum.
Judgment (Can it recognize good writing?): Tests to see if the model has the taste to make existing writing better, again for Spiral as well as our internal editorial needs.
If you've ever wondered how a company built on words and AI tests how AI does with words, here's what happened when we put Sonnet 4.5 to the test.

AI should handle that
Looking for a Notion power user? Notion Agent is exactly that, and it completes everything you need to get done in Notion, with memory and intelligence. It updates databases, drafts documents, and wrangles feedback across tools. It knows every building block, searches everywhere you work (Slack, Google Drive, your workspace), and personalizes to match your style. Give it a goal and let it work.
The blind taste test: Controlling for recency bias
When AI companies release new models, they publish benchmark scores—standardized tests measuring performance on tasks like coding, math, reasoning, tool use, and so on. The scores get packaged into charts showing how the new model stacks up against competitors.
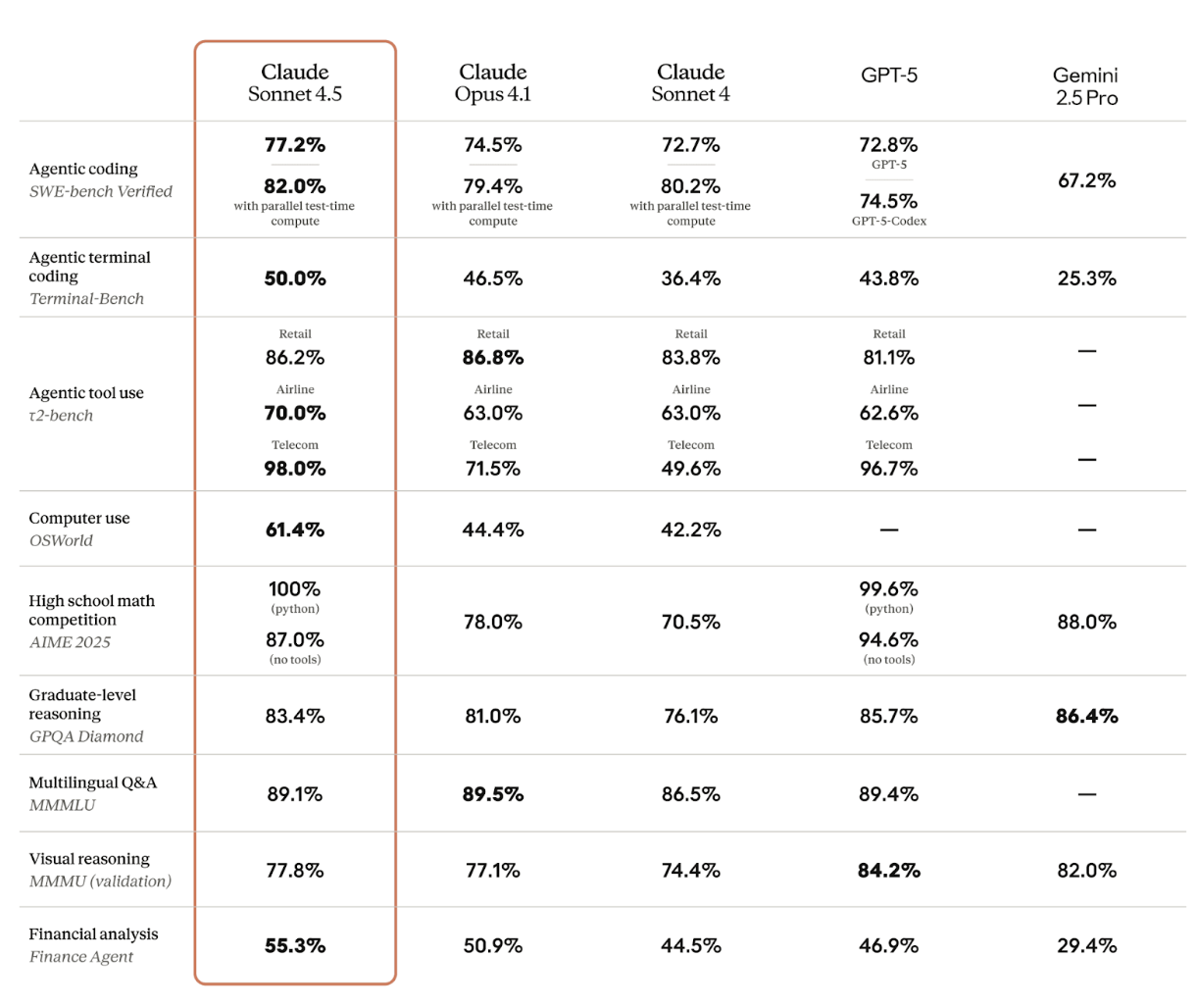
When a new model launches with better benchmarks, it's easy to assume the output must be better, too—especially when you're eager for an upgrade. But "better" in writing is subjective, and recency bias is real. So we run blind taste tests to keep ourselves honest: Do we really think this model is better, or is it just a shiny new object?
For Sonnet 4.5, Danny ran a quick experiment with Spiral in our Every Discord server. He gave the same prompt (Spiral’s system prompt for producing ) and the same task (summarize this article in an X post) and got six outputs, three each generated by GPT-5 and Sonnet 4.5. (Note: This is a core part of how Spiral works—it produces three options of each draft so users can choose the one they like best.) No labels, obviously—just emojis to register your vote and a couple of guiding questions to get at the heart of the issue: Which one is written better?
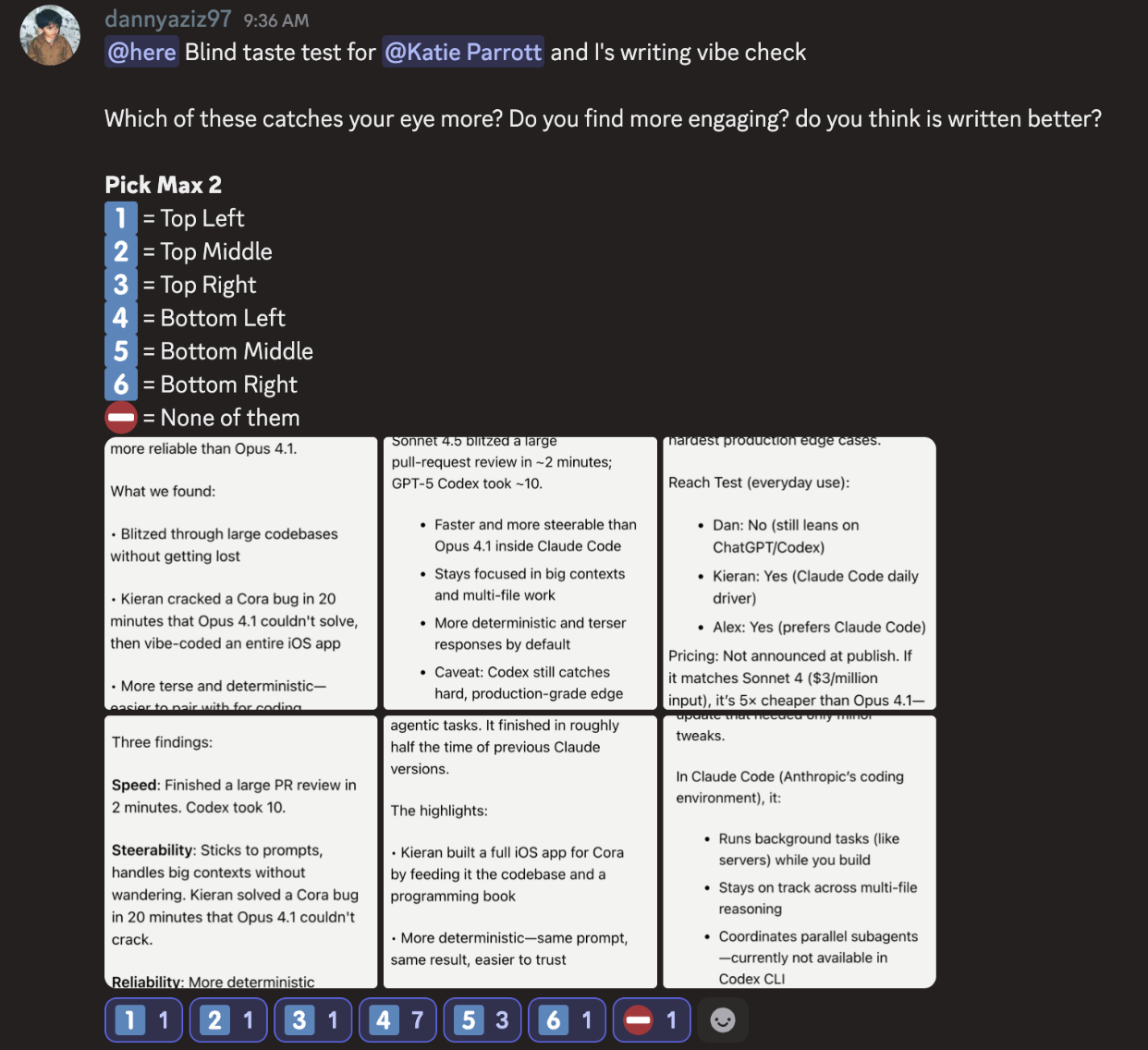
Sonnet 4.5 came in first and second. It struck the right balance of providing context while also identifying and articulating the most interesting points of the article we asked it to summarize. GPT-5 either jumbled the context, misidentified the main lessons, or both.
General writing quality: Does it ‘sound like AI’?
Beyond blind preference tests, we need to assess the draft quality we'd encounter in daily use: Does the writing sound natural? Does the model respond well when you ask it to adjust tone or style? How much editorial work does a typical draft require?
In other words: How likely is someone to read the output and say, “This sounds like AI”?
I generated a 1,500-word draft about my experiences with Notion’s new AI features with Sonnet 4.5 and read through it looking for some of my personal AI-writing pet peeves:
Correlative constructions ("Not X, but Y"/"Not just X. It's also Y"): Only two instances. Previous models would pepper these throughout, using them as crutches whenever they needed to add emphasis or contrast.
Rhetorical questions as filler: Mostly absent, although there were a few—"And honestly? It was impressive"—that I had to smooth out. There was also no "Here's the thing:" followed by a pivot that goes nowhere.
Profound-sounding nonsense: Still present but less frequent. I caught one phrase that sounded smart on first pass but meant nothing on examination: "the kind of optimism reserved for things you've been dreading." What does that even mean? But fewer slipped through than with earlier models.

When I used Sonnet 4.5 inside my Working Overtime project—the one trained on my voice and patterns—the output was a solid A or A-minus, whereas GPT-5 I’d put at an A- or B+. GPT-5 doesn’t appear to like producing large quantities of text at a time and tends to collapse into bullet points when asked to generate more than a few paragraphs at once. By contrast, Sonnet 4.5 can draft for days. It picks up direct language from my dictation and keeps the quirks and corners of my natural style instead of smoothing it into generic AI voice.
Also notable is that Sonnet 4.5 shows better judgment about what “good” means. When I gave it two versions of a draft—one I'd written outside my Working Overtime project, using what I refer to as “straight Claude,” and the other generated within the project with my context—and asked it to keep the best parts of each, its interpretation of “good” mostly matched my own.
Sonnet 4.5 just feels different. It’s hard to say whether that difference is an objective step up in performance—like in The Prisoner of Azkaban when Harry Potter goes from a Nimbus 2000 to a Firebolt, “the fastest broom in the world,” with “unsurpassable balance and pinpoint precision”—or simply a slight difference in handling that’s a matter of preference.
Short-form suggestion test: Does it know what ‘good’ means?
A model can follow instructions and generate text, but does it understand what makes writing work? Can it tell the difference between clever and confusing? Does it know when a phrase will land with a first-time reader versus only making sense to machines?
To find out, Danny asked Sonnet 4.5, Opus 4.1, and GPT-5 to suggest ways to make an X post more engaging. Both Claude models gave suggestions that felt... off.
First, Opus suggested that Danny’s weird habit of having AI analyze all his social relationships and make recommendations through the note-taking app Obsidian was something “any reasonable person would do.” If it was trying to be self-aware or sarcastic, it whiffed. If it wasn't being sarcastic, then framing it as something "a reasonable person" would do doesn't make sense.

Sonnet 4.5’s suggestions were less bizarre but equally unhelpful. It opened with "inner-circle energy"—terminology that makes no sense if you haven't read the full piece. It’s the kind of phrase that sounds clever in the model's context window but falls flat when someone encounters it cold.

GPT-5, meanwhile, gave succinct, reasonable suggestions that didn't presume the reader had been briefed on terminology they hadn't seen yet. There were no formulaic phrases wedged where they didn't belong, just straightforward improvements.

When you need to improve something short—like a tweet or headline—you might want a model that simply tightens what you've written rather than tries to reinvent it. The same qualities that make Sonnet great for longer projects—its eagerness to reimagine, invent new phrases, and push your thinking—can work against you when all you need is minor cleanup.
Writing workflow test: Interview to outline to draft
Most model tests evaluate isolated capabilities: summarization, rewriting, tone matching. But writing is messier—it involves exploratory conversation, structural decisions, and iterative refinement. A model needs to work across the entire process—from helping me figure out what I’m trying to say, through structuring an argument, to producing a draft that doesn't require a complete rewrite.
I ran my full drafting process end-to-end, starting where I always do: by having the LLM interview me. Here’s how I kicked off a recent draft: "I have an idea for a Working Overtime essay about my experience working with Notion's new AI capabilities. I'm going to give you some notes I've started, and then I'd like you to ask me questions, one at a time, to help develop this concept into an essay."
This is where Sonnet 4.5 behaves differently from GPT-5 or Opus 4.1.
With Sonnet, Claude’s conversational style became more engaged. Instead of firing off the next question, it paused to reflect on what I'd said: "You're saying the middle ground is actually the worst position." Then it explained why it was asking what it was asking.

The depth of the questions caught me off guard. It asked things that had me reconsidering my own stance; maybe I hadn’t thought through the argument as clearly as I’d assumed. It felt like the interview was being led by a genuinely curious, human thought partner.

When I asked for an outline, Sonnet 4.5 came back with a solid structure. I had to make a judgment call about how deep I wanted to go into the background of Notion as a product and a company, and which sections may need rearranging or expanding—all things I’d expect to do with any model.

Course corrections were still necessary. It hallucinated details where it needed to fill in context and invented transitions that sounded plausible but missed the point. But that's where Sonnet 4.5's speed becomes its own advantage: The cost of iteration is low. If you don't like something, you can regenerate in seconds, try a different angle, give additional context, and you won’t have to waste time waiting for the model to contemplate its life choices before giving you a response.
The AI editor test: When your standards become the model's standards
If we're using a particular model for drafting, we need to trust it for editing, too—otherwise we're stuck context-switching between tools. How does Sonnet 4.5 handle the role of style guardian? I put it up against other models in powering Every’s AI editor to see how well it could apply our editorial standards.
One catch: ChatGPT has a significantly shorter limit for custom instructions than Claude, so to make this a true side-by-side comparison, I had to compress our official custom instructions below 8,000 characters. That may have handicapped how GPT-5 performed.
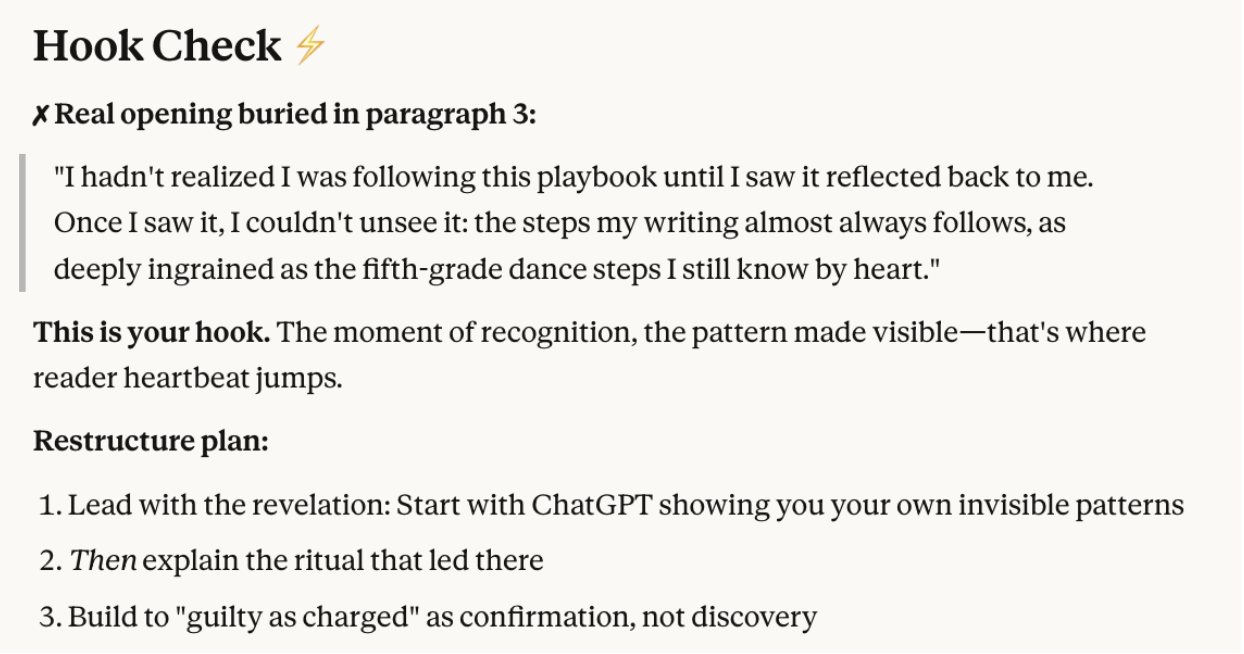
Hook check
Sonnet 4.5 appears to be less easy to please than Opus 4.1. Where Opus told me my hook—the opening of an article that draws people in—was already in the right place, Sonnet pushed me to rearrange it slightly. Whether or not to act on something like that is ultimately a question of taste, but it's something to think about. GPT-5, meanwhile, offered the least helpful feedback of the three—vague encouragement without substance.


Thesis check
All three models told me that my thesis needed sharpening. GPT-5 went for a straight "how to"-style tease. Opus 4.1 got lyrical with talk of "recursive self-discovery" and "mirrors" (LLMs love talking about mirrors, for some reason). Sonnet 4.5 got creatively ambitious, pushing for a coined term to stake a conceptual claim on my process. It's probably trying too hard, but I'd rather have an editor prone to megalomania than one that plays it safe.

Language fixes
Sonnet 4.5 was the most thorough when it came to catching finer-grained language distinctions. It found 15 hedges—words like “maybe,” “kind of,” or "actually" that weaken the stance the writing is taken—versus Opus's 4 and GPT-5's lone catches. Interestingly, GPT-5 did the best at identifying correlative constructions ("not X, but Y" and similar patterns that have become calling cards of GPT-generated text).

Sonnet 4.5 is tough, but fair. Again, this section has to be caveated with the fact that we adjusted our prompt to control variables for this Vibe Check. Paired with our full instruction set, Sonnet 4.5 is significantly more thorough—it identified 87 total line-level fixes, which is about what a human editor might catch. The fact that Claude’s custom instruction field can accommodate longer prompts is itself a feature to chalk up in the “wins” category for Claude as compared to ChatGPT.
The Reach Test: Will we use it?
There’s only one question that matters: Which tool do you reach for when you're working with words?
Danny's verdict: Sonnet 4.5 is likely taking over as the main writing model inside Spiral, pending more testing. It's already replaced other models for conversational interactions with users and for judging writing quality. The speed and steerability won out over GPT-5, our previous pick.
My verdict: I’m already using it (on this piece, for example). Within 48 hours of testing Sonnet 4.5, I'd officially broken up with ChatGPT for writing purposes. It's not objectively superior to GPT-5 or Opus 4.1 in every dimension, but it’s good enough that I feel safe running my full writing and editing process end-to-end inside Claude.
The only way to know if a model works for you
If you're deep in the AI writing weeds, experimenting with different models for different tasks, Sonnet 4.5 might be the "good enough at everything" option that simplifies your decision. It's not the best at every task—GPT-5 won the short-form test, for instance—but it's strong enough across the board that you can stop chatbot-hopping.

The bigger lesson is that the only way to know if a model works for your writing is to run it through your work. Not someone else’s “magic prompt” or one-off experiments, but the messy Tuesday-night workflows where you need words by Wednesday morning. Your criteria won't match ours. If you write marketing copy, you might not care about interview-style collaboration. If you edit technical documentation, creativity matters less than accuracy. But the framework—blind tests to control for hype, workflow compatibility checks, editorial reliability measures—transfers even when the specifics don't.
So take a weekend and run your process through whatever model you're evaluating. Use your actual drafts, your revision patterns, and the work you do when nobody's watching. See what breaks, what improves, and whether it changes which tools you reach for.
For me, it did. My browser has one fewer tab open.
Katie Parrott is a staff writer and AI editorial lead at Every. You can read more of her work in her newsletter.
To read more essays like this, subscribe to Every, and follow us on X at @every and on LinkedIn.
We build AI tools for readers like you. Write brilliantly with Spiral. Organize files automatically with Sparkle. Deliver yourself from email with Cora. Dictate effortlessly with Monologue.
We also do AI training, adoption, and innovation for companies. Work with us to bring AI into your organization.
Get paid for sharing Every with your friends. Join our referral program.