
Many AI investors are betting that the biggest AI models will win—that scale and compute beat everything else. But recent research and market moves suggest otherwise. Alex Duffy, who runs a company that uses games to make AI models better, explains what he’s seeing from inside this market—and why the data your company already has might be worth more than you think.—Kate Lee
My friend recently received a strange email. The sender, someone at a large data provider for AI labs, wanted to know if my friend could share data on things like the number of Dropbox files his company had stored or the number of tickets it had processed on Zendesk. Compensation, commensurate with the data, was promised.
He showed me the email, curious. To me, the founder of a company that sells data and environments to AI companies to help them train models better, this was just another sign of the robust market forming for making AI better.
Reddit, Shutterstock, and News Corp are making hundreds of millions a year licensing their high-quality data to companies training AI, and those contracts are growing about 20 percent annually, according to their quarterly filings. News Corp’s CEO put it bluntly: “We’re essentially an input company [for AI].”
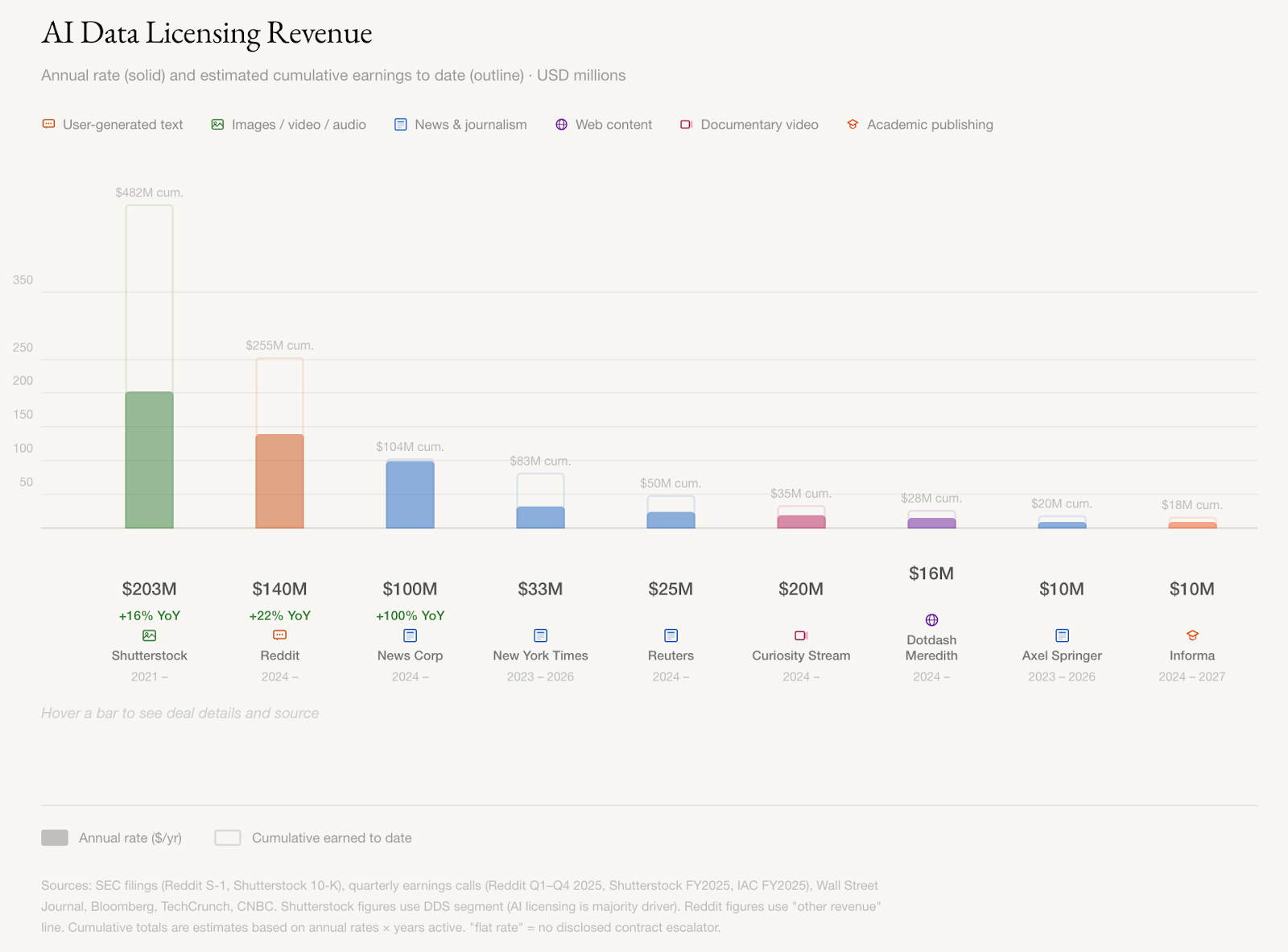
Academic publishers, documentary archives, game studios, and companies sitting on years of enterprise data have all been courted for the seeds of intelligence needed to train the next generation of models. Mercor, which provides data to AI labs for training, became one of the fastest-growing companies in history before losing four terabytes of data to hackers last week. Competitors Turing, Handshake, and SID.ai are scrambling to fill the gap, reaching out to founders and anyone with access to buy operational data, similar to the request my friend received.
While some experts have speculated that general models will win out in performance over specialized models—that scale and compute will beat curation—the success of these companies shows that the market is making a more nuanced bet.
A small model trained on fewer than 2,000 examples from real lawyers, bankers, and consultants recently beat all but the best frontier models on corporate legal work, at a fraction of the price, since they used an open-source model and now only face the cost of running it.
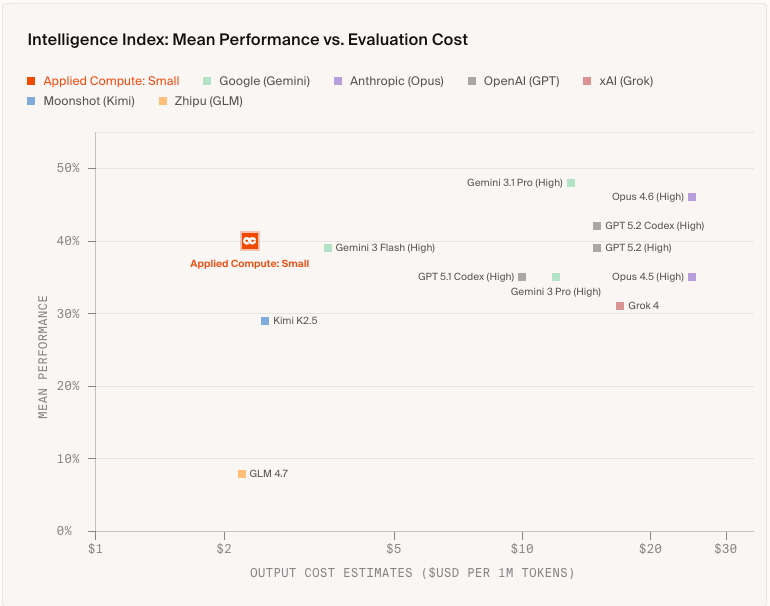
More companies are racing to catalogue and operationalize human knowledge, and whoever leads this market may shape which ideas, which history, and whose principles inform the most powerful tools we’ve ever built.

How to stop babysitting your agent
Agents can generate code. Getting it right for your system, team conventions, and past decisions is the hard part. You end up wasting time and tokens in the correction loops. More MCPs, rules, and bigger context windows give agents access to information, but not understanding. The teams pulling ahead have an organizational context engine to give agents exactly what they need for the task at hand.
Join us for a free webinar on April 23 to see:
- Where teams get stuck on the AI maturity curve and why common fixes fall short
- How a context engine solves for quality, efficiency, and cost
- Live demo: the same coding task with and without an organizational context engine
If you want to maximize the value you get from AI agents, this one is worth your time.
The data with value
The data sources with the most value share two traits:...
Become a paid subscriber to Every to unlock this piece and learn about:
- The gap researchers found between what AI benchmarks measure and what people get paid to do
- The two traits that make data valuable to AI labs
- How any company can profit from proprietary data


What is included in a subscription?
Daily insights from AI pioneers + early access to powerful AI tools
 Front-row access to the future of AI
Front-row access to the future of AI
 In-depth reviews of new models on release day
Playbooks and guides for putting AI to work
Prompts and use cases for builders
In-depth reviews of new models on release day
Playbooks and guides for putting AI to work
Prompts and use cases for builders
 Bundle of AI software
Bundle of AI software