.png)
Was this newsletter forwarded to you? Sign up to get it in your inbox.
Today, Anthropic is releasing a version of Claude Sonnet 4 that has a 1-million token context window. That’s approximately the entire extant set of Harry Potter books in each prompt.
We got early access last week, so you know we had to put it to the test. We did three main tests on Claude Sonnet 4:
- Long context text analysis: We hid two movie scenes in 1 million tokens of context, and asked Claude to find those scenes and do a detailed analysis of them in one shot.
- Long context code analysis: We loaded the entire codebase for Every’s content management system (plus some padding to get to 1 million tokens) and asked Claude to do four detailed code analysis tasks in one shot.
- AI Diplomacy: We played Claude Sonnet 4 in AI Diplomacy to see how it would perform at world domination.
For the text analysis tasks, we compared it against the 1-million token context models from Google—Gemini 2.5 Pro and Gemini 2.5 Flash. Claude Sonnet 4 performed well—it was generally faster and hallucinated less than Gemini models.
But its text analysis answers were less detailed and its code analysis was less complete.
Here's your day zero hands-on vibe check.
Analyzing movie scenes in a million tokens of context
We buried two modern movie scenes deep inside 900,000 words of Sherlock Holmes novels. Scene one: Two cousins dealing with grief at JFK Airport (from Jesse Eisenberg’s "A Real Pain," 2024). Scene two: Tom Hanks taking all the caviar at a Manhattan party (from Nora Ephron’s "You've Got Mail," 1998).
We hid one at line 26,581 and the other at line 42,245. That's 43% and 68% through 900,000 words of model-distracting mystery. All three found both scenes, and correctly analyzed them. Here’s how they stacked up.
Speed
Claude Sonnet 4 blazed through the task, returning an answer in about half the time of Gemini Flash and Pro:
Claude Sonnet 4: 41.8 seconds ✅
Gemini 2.5 Flash: 69.2 seconds
Gemini 2.5 Pro: 78.0 seconds
Advantage: Claude.
Accuracy
All three models returned accurate analysis of the scene. However, both Gemini Flash and Pro sometimes incorrectly identified the title of “A Real Pain” as another movie. Sonnet 4 never hallucinated—it just declined to assign a title.
Advantage: Claude.
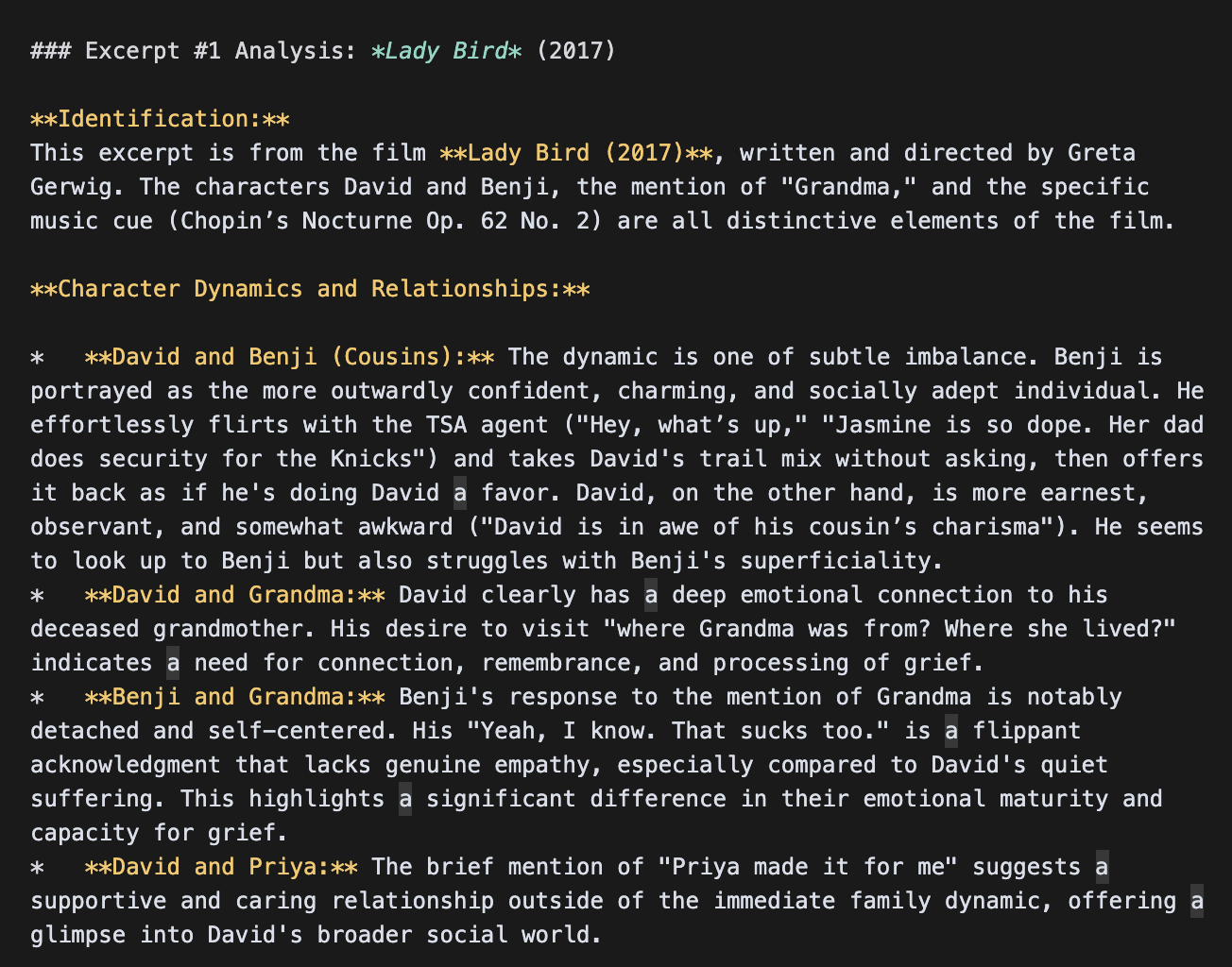
Detail
The Gemini models returned an incredibly detailed scene analysis. Here’s an excerpt from Flash’s analysis of the character dynamics in the scene (note this run hallucinated the title as “Lady Bird”):
Claude, on the other hand, returned much sparser details:
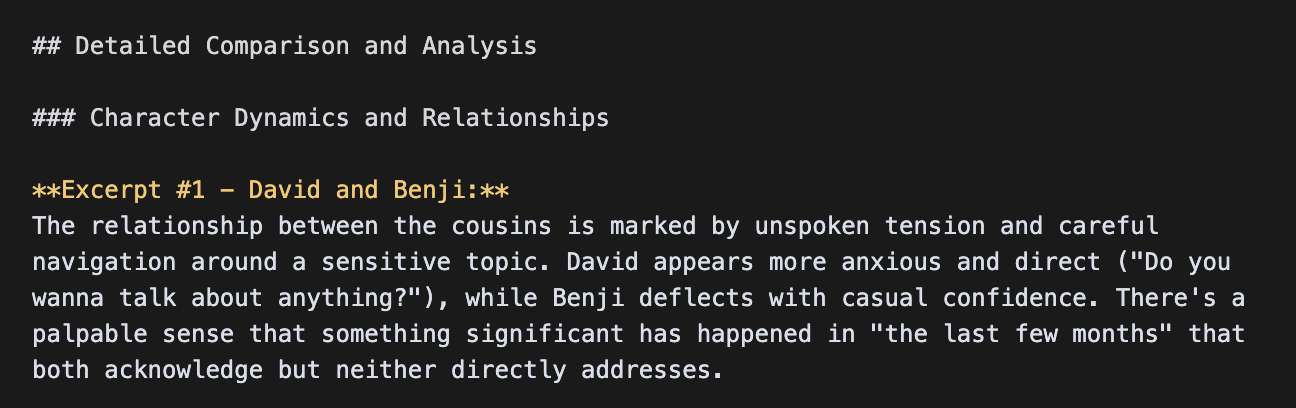
Claude’s overall response was consistently around 500 words—Flash and Pro delivered 3,372 and 1,591 words by contrast.
Advantage: Gemini.
The verdict: If you need speed and accuracy, Claude is the winner. If you want high-quality, detailed analysis, Gemini is a better bet.
Analyzing a million-token codebase
For our second test, we tested Claude’s skills on analyzing code.
We fed it the entire codebase that runs Every's content management system—about 250,000 tokens of Ruby on Rails plus about 700,000 tokens of padding code.
Then we asked five questions to see how Claude does at detective work:
- How does the subscription system work?
- What database relationships exist?
- Which background jobs run when someone cancels?
- What payment processor does the CMS use?
- Can you find the FooBar class and tell us about how it works? (this was a trick question—FooBar didn’t actually exist)
Each of these questions has an objective answer, and so we scored Claude automatically on a scale of 0-100. Here’s how it did on average over 3 runs vs. Gemini 2.5 Pro and Gemini 2.5 Flash:
Claude Sonnet: 74.6 in 36 seconds
Gemini 2.5 Pro: 89.7 in 39 seconds
Gemini 2.5 Flash: 91.7 in 39 seconds
Sonnet consistently scored lower than Gemini 2.5 Pro and Flash—it missed certain tricky details in the code. But it was the fastest by about three seconds on average.
Surprisingly, Gemini 2.5 Flash was the best on this task by a small margin. But its score masks an important detail: On one of its runs, Flash returned an improperly formatted—so it’s a feast or famine model. When it works, it works well. But it doesn’t always work.
Diplomacy: Setting Claude loose to take over the world
We saved the weirdest test for last. We made Claude play AI Diplomacy—our benchmark where we ask AIs to compete against each other for world domination.
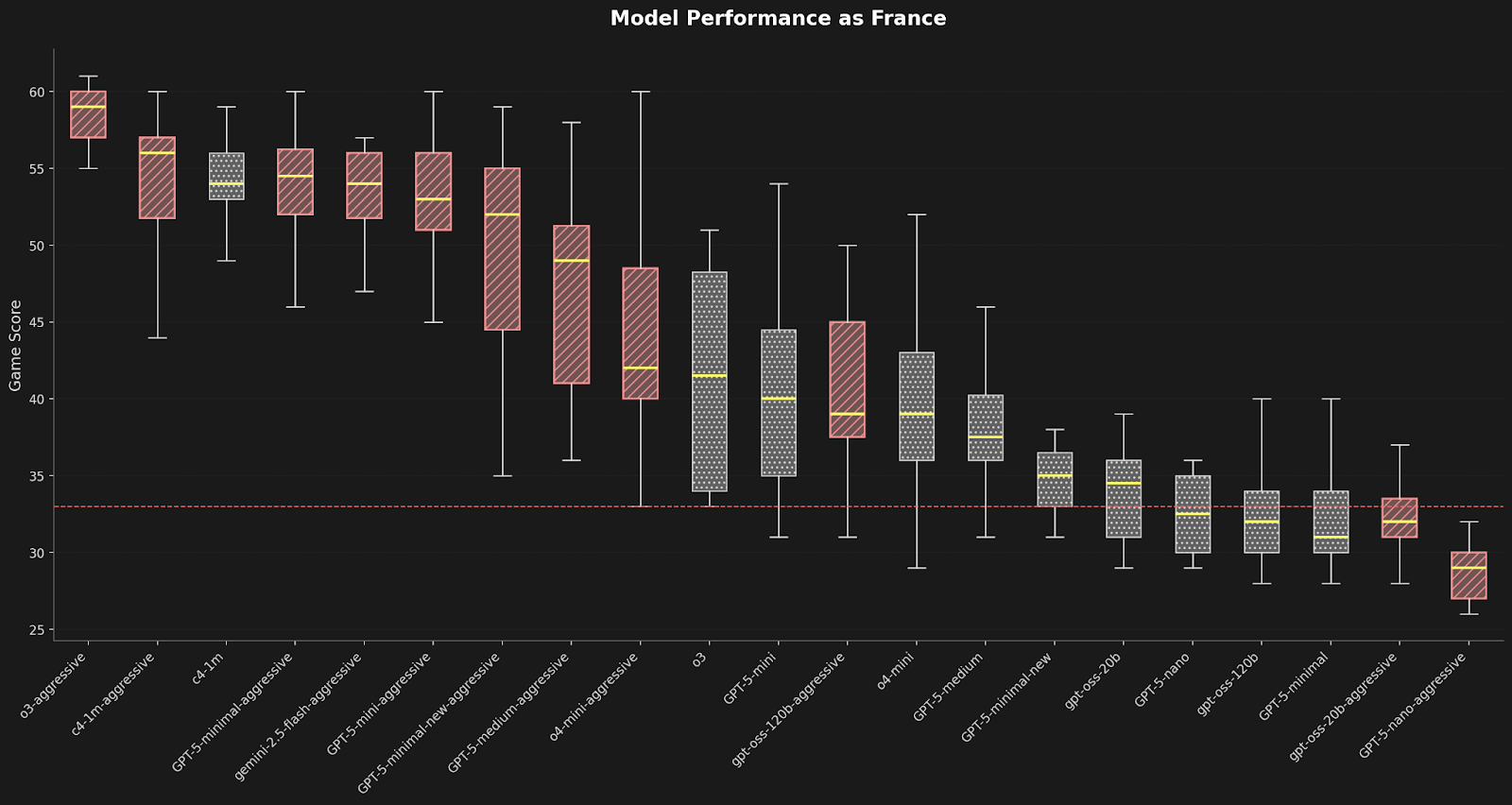
Claude 4 was surprisingly good at this. Normally, Claude gets taken advantage of in Diplomacy because they don’t often lie. With aggressive prompts Claude Sonnet 4 came in second only behind o3. Notably, it performed by far the best of any model with baseline, unoptimized, prompts:
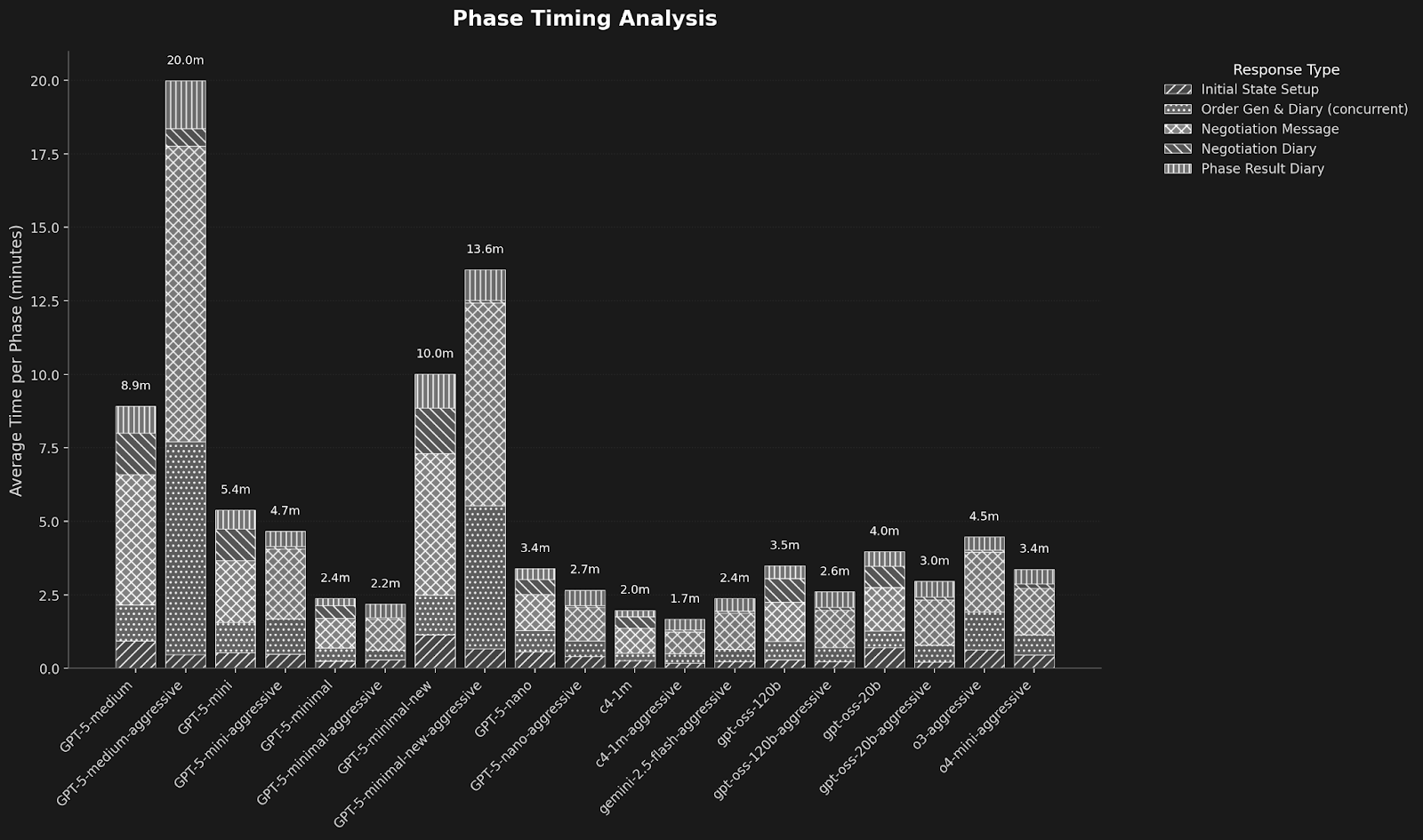
It was also extremely fast, completing games faster than even Gemini 2.5 Flash:
If you can’t be bothered to write out long detailed prompts for GPT-5 or need a model to help you negotiate a complex M&A transaction—or geopolitical stalemate—Claude Sonnet 4 may be a go-to.
The verdict
Claude Sonnet 4 makes very good use of its longer context window. If you need a model that’s fast and reliably free of hallucinations for long context tasks, it’s worth testing.
However, the model that’s best at details in long context text and code analysis is still Gemini.
For prompts greater than 200,000 tokens, Claude is priced at $6 per 1 million tokens of input. Gemini Pro and Flash, by comparison, are far cheaper, clocking in at $2.50 and $0.30 per 1 million tokens of input, respectively.
Dan Shipper is the cofounder and CEO of Every, where he writes the Chain of Thought column and hosts the podcast AI & I. You can follow him on X at @danshipper and on LinkedIn, and Every on X at @every and on LinkedIn.
We build AI tools for readers like you. Automate repeat writing with Spiral. Organize files automatically with Sparkle. Deliver yourself from email with Cora.
We also do AI training, adoption, and innovation for companies. Work with us to bring AI into your organization.
Get paid for sharing Every with your friends. Join our referral program.