AI can be exhilarating and destabilizing. Just when you think you have your setup figured out, a powerful new model drops—or, in the case of Anthropic’s Fable 5, gets abruptly disabled. Today, we explore this instability from multiple angles: Staff writer Katie Parrott maps the grief (and coping mechanisms) that accompanied the Fable ban and shares a practical playbook for the next time a model you depend on disappears, head of growth Austin Tedesco explains how loops are causing him to rethink his approach to working with AI, and GitHub chief operating officer Kyle Daigle tells AI & I guest host Mike Taylor how the company is responding to an agent-generated surge in commits.
‘AI & I’: Can GitHub be for everyone?
Today we’re releasing a new episode of our podcast AI & I. Head of tech consulting Mike Taylor guest hosted this week and spoke to GitHub COO Kyle Daigle about how the company is responding now that everyone—and their army of agents—can ship code.
The volume is extreme: Last year, there were 1 billion commits on GitHub. This year, that figure will safely exceed 14 billion, Daigle says, which puts GitHub in an important but delicate position: It must help developers handle agent-generated code without dictating which pull requests communities should trust or merge.
Watch on X or YouTube, listen on Spotify or Apple Podcasts, or read the transcript. And for a behind-the-scenes look at the making of the podcast, check out Mike’s piece on his decision to ditch standard-issue prep in favor of building and mock interviewing an AI version of Daigle.
Here are the highlights:
- The developer versus non-developer distinction is disappearing: GitHub has long taken an expansive view of who counts as a developer, but AI has blown up the definition entirely. Legal, finance, sales, and marketing professionals are using the GitHub Copilot app to build prototypes and apps. “A lot of the folks that the industry would call knowledge workers, or just non-developers by trade, are using these tools,” Daigle says.
- Agents can write and review code, but humans decide what ships: GitHub has built agentic code review and merge tools to help developers handle the surge of pull requests, but people who run open-source projects should ultimately decide which outside submissions they merge. “We want to provide tools,” Daigle says, “but really leave them in control.”
- Daigle runs a daily loop on himself: In AI, a loop is a cycle in which an agent does work, evaluates the result against a goal or standard, incorporates feedback, and repeats the process until the task is complete or the output improves. Daigle uses the same workflow to improve his communication style—each day, an agent reviews a rolling seven-day window of his emails and Slack messages, identifies patterns, provides constructive feedback, and checks whether he incorporated its advice.
Miss an episode? Catch up on Dan’s recent conversations with LinkedIn cofounder Reid Hoffman; the team that built Claude Code, Cat Wu and Boris Cherny; Vercel cofounder Guillermo Rauch; podcaster Dwarkesh Patel; and others, and learn how they use AI to think, create, and relate.

Under the hood: How Dropbox engineers are building AI that understands you
Work today is scattered across tools that don’t talk to each other—and none of them have the full picture of what you actually need. On the Working Smarter podcast, Dropbox engineers share how they are building context-aware intelligence that connects to all the tools your team uses for work—so you get AI that works wherever you do.
With episodes on context engineering, multimodal search, agentic AI, security, and more, Working Smarter shows you what it takes to build AI that helps you work smarter. The tools you trust, explained by the people who made them. Listen to the latest episodes of Working Smarter wherever you get your podcasts.
Inside Every
Loops, loops, loops
“I’m super loop-pilled,” says head of growth Austin Tedesco. He’s not alone. Loops—which have AI tackle a goal through iterative cycles of completing a section of the task, reviewing the results, incorporating the learnings, and generating the next step—have become a hot topic of discussion here at Every in recent days.
While some have been using them for a while—looking at you Kieran Klaassen, the father of loop-based engineering philosophy, compound engineering—newer, more powerful models have made this approach possible for non-code-based workflows, too.
For Austin, Fable—RIP, at least temporarily—was what made the power of loops click into place. The “aha” moment came when he gave the model a simple prompt:
Build me an NBA simulation game that’s like Football Manager: basically NBA 2K Dynasty mode without gameplay. I want to pretend I’m an NBA general manager and make real transactions. Build it through the /LFG flow—the compound engineering workflow that brainstorms, plans, builds, reviews, and improves—then keep looping overnight.
When he woke up, he had a working NBA front-office simulator. What floored him was how the model worked through the task: Fable would hit a stopping point, review what was missing, write itself a new one-paragraph prompt, and keep going. At one point, it realized the game needed NBA-specific salary-cap logic, including rules around teams renouncing free agents before July 1. It also simulated a full season and logged what happened, so it could inspect the game’s behavior.
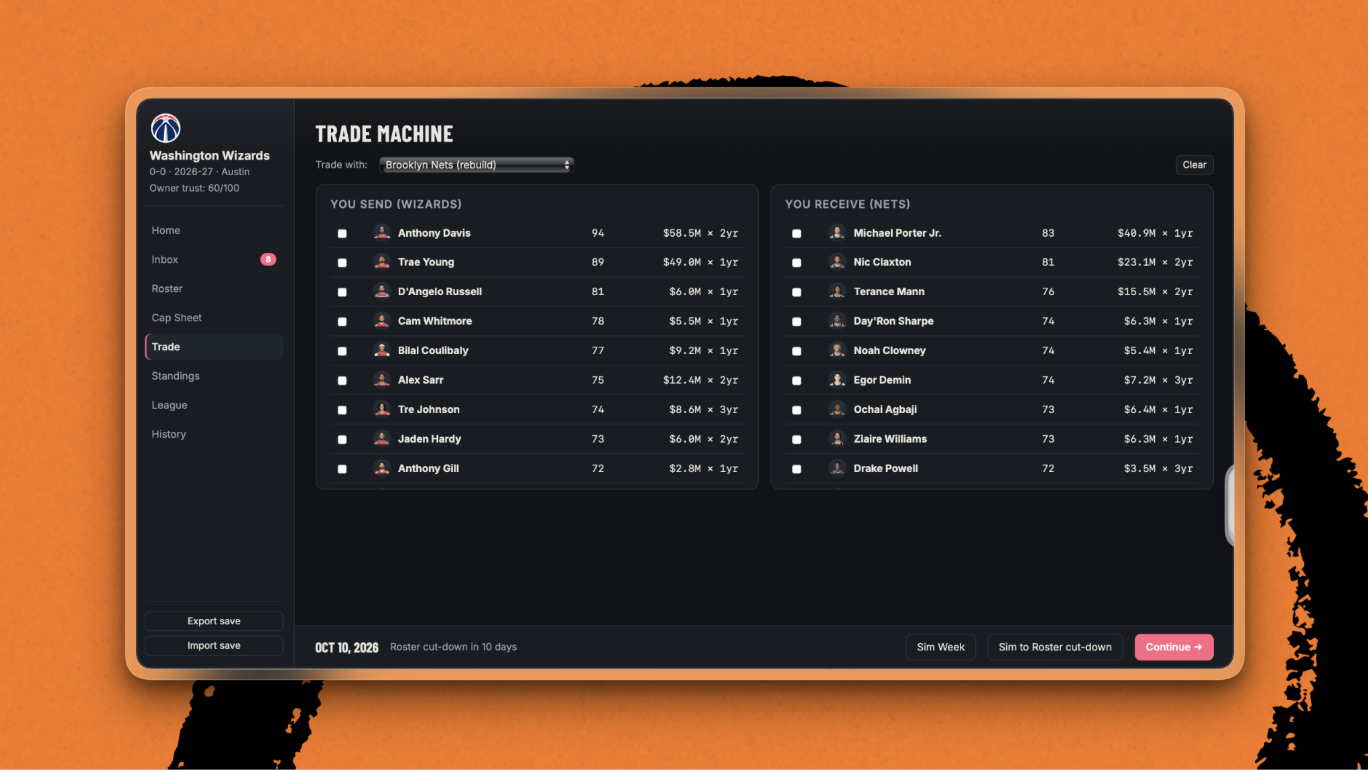
Every’s growth team has used the same setup to improve our subscription flow and create a net-new pricing page. We supplied the goal, the context, and the desired output, and the agent looped through the rest.
Even though Fable is temporarily inaccessible, Austin is trying to recreate pieces of the same cycle in Codex with /goal, a feature that gives Codex a persistent objective to work toward across a longer-running session.
Get CEO Dan Shipper’s Fable prompt for loops or steal Austin’s workflow:
- Define the problem and output. For example, “Our subscription flow and pricing page aren’t converting the way they should. Find the weak spots and produce new experiments we could ship or mock in Figma.”
- Give the agent a way to review its work. Provide the materials it would need to judge whether an idea is good: who it’s building for, what those users are trying to do, what their current experience looks like, where the data says people get stuck, what competitors do differently, and what constraints it needs to work within. Then ask it to test each idea against that context before writing its next prompt.
- Set the loop in motion. Tell the agent: “When you hit a stopping point, write yourself a one-paragraph prompt for the next improvement and keep going until the outcome is materially better.” Let it generate pricing-page variants, Figma experiments, or site changes. Then review the outputs and decide what’s good enough to act on.
Pulse Check
Your favorite model will die
When Fable—the best coding model Every had tested—shut down on June 12, the tech community lived through a compressed version of the five stages of grief. It was a preview of what you should expect every time a model goes away. Here’s what helped, and what to do the next time the weights vanish.
Save the session before you need it
When a model you lean on is about to change, don’t rush to replace it—first, stop throwing away the evidence. The model’s plans, edits, tests, slip-ups, and fixes live on in chat histories in web apps and log files on your computer, and you can reuse that record.
One Fable user, posting as CuddlySalmon, kept a session open from before the shutdown and reported that it still seemed to carry Fable’s context after Claude fell back to Opus 4.8—though they admitted that might be wishful thinking. Another used Codex helper agents to dig design choices out of old Fable runs.
Do this now: Export a few sessions from whatever model you depend on, and save the full trail of what it did, not a tidy summary. The weird little choices are what you’ll want later.
Build while you have the opportunity
As the shutdown news hit Every’s company Slack, Dan gave the team one order: “quick BUILD EVERYTHING.” In the three days we had, Every took maximum advantage of the opportunity. We used Fable to build a Lord of the Rings version of graphics editor Kid Pix, an open-source deck-building tool, and an interactive shader tool, each in an afternoon.
Do this now: When a new frontier model comes out, give your team the time and space to experiment in the first few days. You may not get another three-day sprint like that.
Determine which work needed the frontier model
The morning after the shutdown, Dan asked the team what they’d do if Fable stayed gone. Kieran said that he would use Opus, like before. Naveen Naidu, who runs our voice app Monologue, said that he would go back to Codex. Willie Williams, Every’s head of platform, would keep Codex as his daily tool and move the Plus One factory back to Opus.
Most of your work never needed the top model in the first place. Some does. While building hands-on-deck, an open-source slide tool, with Fable, Nityesh Agarwal—Every’s senior AI engineer—noticed that the more ambitious his ask, the more ambitious the model’s output—each one pushed the other higher. On Opus that pull was gone. He could still do the work; he’d just lost the nudge to attempt the bigger version.
Do this now: Take one real Fable-size task and run it on your backup model. If it passes, that work never needed the top model, so stop paying extra for it. If it fails, you’ve found work worth protecting, and you know where to put your effort.
Build for the model to disappear
Treat the outage as a fire drill for moving work between models, which means that the work needs to be portable and you need to be able to check for mistakes.
On portability, Christopher Allen, who runs the nonprofit Blockchain Commons, built a Claude workstream kit that captures the goal, the to-do list, the choices made, the lessons learned, the current task, the next step, and the blockers—all in plain text files tracked by Git. Because everything lives in the files rather than the chat history, a new model can pick the work right up—nothing key gets stranded in a conversation that no longer exists. On verification: A portable handoff isn’t enough if you can’t tell whether the work is correct. You also need a built-in check—a test of a “done” rule the model can demonstrably pass—that proves it’s so.
Do this week:
- Run one live task through a backup. Pick something you do often, with an output you can judge.
- Write down what the new model couldn’t recover. Move those choices, examples, preferences, and “done” rules into project files.
- Add a test that proves the job is done. The fastest backup is the model that can show its work, even if its style leaves you cold.
Fable may come back. Either way, the next model you build on shouldn’t be able to take your work down with it.—Katie Parrott
Discuss
“I feel like I got on the last plane out of Vietnam. I don’t think I can plan for a normal-length career, at least in this field.”—Christopher Pack, software developer, in the Wall Street Journal
For decades, a tech degree was the surest ticket to a stable, high-paying job. (Hence all the “learn to code” jabs directed at liberal arts majors.) Now, MVP applicants, and entry-level and mid-career software engineers are competing for a shrinking number of available roles as AI consumes more of their jobs. Per the Journal, even experienced programmers are bracing for layoffs by hoarding cash, making risky stock market bets, or considering a career change.
Laura Entis is a staff writer at Every. You can follow her on LinkedIn. Katie Parrott is a staff writer at Every. You can read more of her work in her newsletter.
To read more essays like this, subscribe to Every, and follow us on X at @every and on LinkedIn.
For sponsorship opportunities, reach out to sponsorships@every.to.
Help us scale the only subscription you need to stay at the edge of AI. Explore open roles at Every.